
25 mrt. 2021
6 minuten

Door gebruik te maken van de nieuwste ontwikkelingen op het gebied van machine learning (ML) technologie breiden embedded ontwikkelaars de kracht van kunstmatige intelligentie (AI) uit tot dichter bij de netwerk edge. De low-power IoT-apparaten van vandaag de dag zijn in staat om geavanceerde ML- en deep learning algoritmen lokaal uit te voeren, zonder de noodzaak van cloud-connectiviteit, waardoor problemen op het gebied van latency, prestaties, veiligheid en privacy tot een minimum worden beperkt. Het is dan wel zaak dat embedded ontwikkelaars beschikken over geschikte low-power apparaten, ontwikkelomgevingen en softwaretools om dergelijke ML-projecten te kunnen realiseren. Denk daarbij aan de DeepView ML tool suite, Glow ML compiler en PyTorch framework.
Door Anthony Huereca, system engineer bij NXP Semiconductors
Tot voor kort waren ML-ontwikkelomgevingen vooral geschikt voor ontwikkelaars met veel expertise op het gebied van ML- en deep learning. Om de ontwikkeling van ML-toepassingen te verbreden is het zaak dat deze omgevingen eenvoudiger in gebruik worden, zodat ook niet-specialistische embedded ontwikkelaars er mee aan de slag kunnen. Daar komt bij dat er voor de relatief recente ML edge-toepassingen andere vereisten gelden dan voor de meer klassieke cloudgebaseerde AI-systemen. Ook is de beschikbaarheid van middelen op IC-, power- en systeemniveau voor embedded ontwerpen beperkter, waardoor andere, nieuwe softwaretools nodig zijn. ML-ontwikkelaars hebben ook nieuwe ontwikkelprocessen bedacht voor intelligente edge-toepassingen, waaronder het gebruik van trainingsmodellen, inference engines voor doelapparaten en andere aspecten van systeemintegratie.
Cross-over
Nadat een ML-model is getraind, geoptimaliseerd en gekwantificeerd, is de volgende ontwikkelfase het implementeren van dit model op een doelapparaat, zoals een MCU of applicatieprocessor, die de ML-functionaliteit zal uitvoeren. Een relatief nieuwe klasse van componenten, die daarvoor geschikt is, wordt gevormd door de zogenaamde ‘cross-over’ microcontrollers. Met cross-over wordt bedoeld dat ontwerpen met deze componenten qua prestaties, functionaliteit en mogelijkheden niet onder doen voor een op een applicatieprocessor gebaseerd ontwerp, zonder dat dit ten koste gaat van de sterke punten van een MCU-gebaseerd ontwerp, zoals gebruiksgemak, laag stroomverbruik en realtime werking met lage interrupt latency.
Een voorbeeld van zo’n cross-over MCU is de i.MX RT-serie van NXP, die is gebaseerd op een Arm Cortex-M kern en kloksnelheden heeft van 300 MHz tot 1 GHz. Deze MCU’s beschikken over voldoende rekenkracht om ML-inferencing engines te ondersteunen en hebben een dusdanig laag stroomverbruik dat ze kunnen worden gebruikt in edge-toepassingen met beperkte stroomvoorzieningen, bijvoorbeeld batterijgevoede apparatuur.
Ontwikkelomgeving
Idealiter kunnen embedded ontwikkelaars een uitgebreide ML-ontwikkelomgeving gebruiken, compleet met softwaretools, toepassingsvoorbeelden en gebruikershandleidingen, om open-source inference engines te bouwen voor een doelapparaat. De eIQ-omgeving van NXP biedt inference-ondersteuning voor Arm NN, de ONNX Runtime engine, TensorFlow Lite en de Glow neurale netwerk compiler. Ontwikkelaars kunnen aan de hand van een eenvoudig ‘bring your own model’ (BYOM) proces een getraind model bouwen met behulp van publieke of private cloudgebaseerde tools. Dit model kunnen ze vervolgens overbrengen naar de eIQ-omgeving om te draaien op de inference engine die is geoptimaliseerd voor de betreffende processor.
Veel ontwikkelaars hebben tegenwoordig ML- en deep learning tools en -technologieën nodig voor hun embedded projecten. Zij zijn gebaat bij uitgebreidere ML-ondersteuning en eenvoudiger gebruik. Denk daarbij aan een end-to-end workflow die ontwikkelaars in staat stelt hun trainingsgegevens te importeren, het optimale model voor hun toepassing te selecteren, het model te trainen, te optimaliseren en kwantificeren, on-target profiling te voltooien en vervolgens over te gaan tot de uiteindelijke productie. Gebruiksgemak zit hem vooral in toegang tot vereenvoudigde, geoptimaliseerde gebruikersinterfaces die hen in staat stellen om een paar opties te selecteren, eenvoudig trainingsgegevens te importeren en het model op het doelapparaat te implementeren.
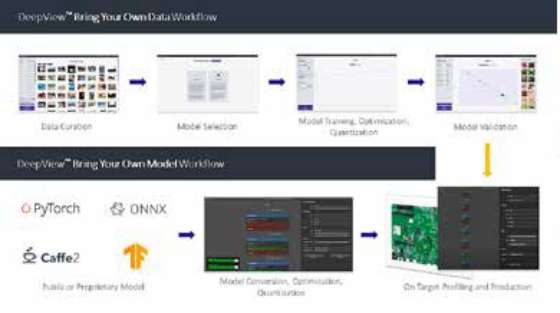 ML-workflowtools bieden ontwikkelaars geavanceerde functies voor het bouwen en implementeren van neurale netwerkmodellen op MCU’s.
ML-workflowtools bieden ontwikkelaars geavanceerde functies voor het bouwen en implementeren van neurale netwerkmodellen op MCU’s.
Vereenvoudigen workflows
Er zijn inmiddels verschillende ontwikkeltools en frameworks die ontwikkelaars kunnen helpen hun ML-ontwikkelingsprojecten te vereenvoudigen. Zo is er de DeepView ML toolsuite van Au-Zone Technologies, een intuïtieve grafische gebruikersinterface (GUI) en workflow die ontwikkelaars in staat stelt om datasets en neurale netmodellen te importeren, vervolgens deze modellen en workloads te trainen en tenslotte te implementeren op een breed scala aan doelapparaten.
NXP heeft onlangs zijn eIQ-ontwikkelomgeving uitgebreid met de DeepView toolsuite. De nieuwe eIQ ML-workflowtool voorziet ontwikkelaars van geavanceerde functies om neurale netwerkmodellen te verfijnen, te kwantificeren, te valideren en te implementeren op NXP-componenten. Grafische profileringsmogelijkheden bieden ontwikkelaars runtime-inzichten voor het optimaliseren van neurale netwerk modelarchitecturen, systeemparameters en runtime-prestaties. Door de runtime inference engine toe te voegen als aanvulling op open-source inference-technologieën, kunnen ontwikkelaars efficiënt ML-workloads en -prestaties op meerdere devices implementeren en evalueren.
Open source compiler
De Glow neuraal netwerk model compiler is een populaire open-source backend tool voor high-level ML frameworks die compiler optimalisaties en codegeneratie van graph neurale netwerken ondersteunen. Met de opkomst van deep learning frameworks zoals PyTorch bieden ML/neurale netwerk compilers optimalisaties die inferencing versnellen op een breed scala aan hardwareplatforms.
De Glow compiler maakt gebruik van een ‘computation graph’ om in twee fasen geoptimaliseerde machinecode te genereren. Eerst optimaliseert het de modeloperatoren en -lagen met behulp van standaard compilatietechnieken. In de tweede backend fase van de modelcompilatie, gebruikt Glow low-level virtual machine (LLVM) modules om doelspecifieke optimalisaties mogelijk te maken. Glow ondersteunt ook een ‘ahead-of-time’ (AOT) compilatiemodus die objectbestanden genereert en onnodige overhead elimineert om het aantal berekeningen te verminderen en de geheugenbelasting te minimaliseren. Deze AOT-techniek is ideaal voor implementaties op MCU’s met weinig geheugen.
 De Glow compiler maakt gebruik van een ‘computation graph’ om geoptimaliseerde machinecode te genereren voor ML-toepassingen.
De Glow compiler maakt gebruik van een ‘computation graph’ om geoptimaliseerde machinecode te genereren voor ML-toepassingen.
Glow-implementatie
Om ML-projecten te vereenvoudigen is Glow door NXP geïntegreerd met de eIQ-ontwikkelomgeving. Het bedrijf heeft op basis van CIFAR-10 datasets als benchmark voor neurale netwerkmodellen de i.MX RT1060 MCU getest om de prestatieverschillen tussen verschillende Glow compilerversies te beoordelen. NXP voerde ook tests uit op de i.MX RT685 MCU, momenteel de enige chip uit de i.MX RT-serie met een geïntegreerde DSP die geoptimaliseerd is voor de verwerking van neurale netwerkoperatoren. De i.MX RT1060 bevat een 600 MHz Arm Cortex-M7, 1 MB SRAM, alsmede functies die zijn geoptimaliseerd voor realtime toepassingen, zoals snelle GPIO, CAN-FD en een synchrone parallelle NAND/NOR/PSRAM-controller. De i.MX RT685 bevat een 600 MHz Cadence Tensilica HiFi 4 DSP-kern in combinatie met een 300 MHz Arm Cortex-M33 kern en 4,5 MB on-chip SRAM, alsmede beveiligingsgerelateerde functies.
De Glow-implementatie van NXP is nauw afgestemd op NNLib, de neurale netwerk bibliotheek van Cadence. Ofschoon de RT685 MCU’s HiFi 4 DSP kern in eerste instantie is ontworpen om spraakverwerking te verbeteren, kan deze component ook een breed scala aan neurale netwerk operatoren versnellen indien gebruikt met de NNLib bibliotheek als een LLVM backend voor Glow. Waar NNLib vergelijkbaar is met CMSIS-NN, biedt deze een meer uitgebreide set van operatoren die zijn geoptimaliseerd voor de HiFi4 DSP. Gebaseerd op de al hierboven aangehaalde CIFAR-10 benchmark presteert de HiFi4 DSP in vergelijking met een standaard Glow compiler implementatie 25x beter in neurale netwerk bewerkingen.
ML-framework
PyTorch is een open-source machine learning framework, dat door veel ontwikkelaars wordt gebruikt voor ML/deep learning projecten en producten. PyTorch is een goede keuze voor MCU’s omdat het minimale beperkingen oplegt aan de verwerking en ONNX-modellen kan genereren, die kunnen worden gecompileerd door Glow. Omdat ontwikkelaars via PyTorch direct toegang hebben tot Glow kunnen zij hun modellen bouwen en compileren in dezelfde ontwikkelomgeving, waardoor minder stappen nodig zijn en het compilatieproces wordt vereenvoudigd. Ontwikkelaars kunnen ook direct vanuit een Python-script bundels genereren, zonder eerst ONNX-modellen te hoeven genereren.
Tot voor kort waren ONNX en Caffe2 de enige door Glow ondersteunde invoerformaten voor modellen. PyTorch kan nu modellen direct exporteren naar het ONNX formaat voor gebruik door Glow. Aangezien veel bekende modellen in andere formaten zijn gemaakt, zoals TensorFlow, zijn er open-source modelconversietools beschikbaar om ze om te zetten naar het ONNX-formaat. Populaire tools voor formaatconversie zijn MMdnn, een door Microsoft ondersteunde toolset om gebruikers te helpen navigeren tussen verschillende deep learning-frameworks, en tf2onnx, dat wordt gebruikt om TensorFlow-modellen naar ONNX te converteren.
Anderen lazen ook


