
17 feb. 1999
2 minuten
Heel handig, als er geen mensen meer aan te pas hoeven te komen om robots te trainen. Kan dat straks in de fabriek? Het kan in elk geval al met spelletjes.
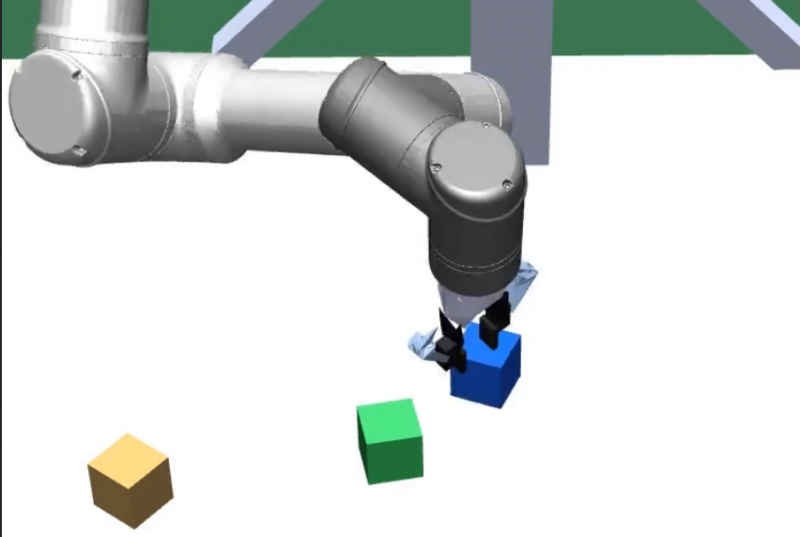
Een virtuele robotarm heeft geleerd om een breed scala aan verschillende puzzels op te lossen – blokken stapelen, de tafel dekken, schaakstukken rangschikken – zonder voor elke taak opnieuw te moeten worden opgeleid. Het deed dit door te spelen tegen een tweede robotarm die was getraind om hem steeds moeilijkere uitdagingen te geven.
De identieke robotarmen Alice en Bob leren door in een simulatie een spel tegen elkaar te spelen, zonder menselijke tussenkomst. De robots gebruiken reinforcement learning, een techniek waarbij AI’s met vallen en opstaanleren welke acties ze in verschillende situaties moeten ondernemen om bepaalde doelen te bereiken. Het spel omvat bewegende objecten op een virtueel tafelblad. Door objecten op een specifieke manier te ordenen, probeert Alice puzzels klaar te leggen die voor Bob moeilijk op te lossen zijn. Bob probeert de puzzels van Alice op te lossen. Al lerend, stelt Alice steeds complexere puzzels op en leert Bob deze beter op te lossen.
Na een training in blokpuzzels, blijkt Bob de opgedane kennis te kunnen generaliseren naar een reeks vergelijkbare taken, waaronder het dekken van een tafel en het rangschikken van schaakstukken. Dit is nieuw: modellen voor deep learning moeten doorgaans tussen verschillende taken worden bijgeschoold. AlphaZero bijvoorbeeld (dat ook leert door spelletjes tegen zichzelf te spelen) gebruikt een enkel algoritme om zichzelf te leren schaken, shogi te spelen, of Go, maar slechts één spel tegelijk. De schaakspelende AlphaZero kan geen Go spelen en de Go-spelende kan geen shogi spelen. Het bouwen van machines die echt kunnen multitasken, is een groot onopgelost probleem op weg naar meer algemene AI.
Een probleem is dat het trainen van een AI om te multitasken een groot aantal voorbeelden vereist. Onderzoekslab OpenAI vermijdt dit door Alice te trainen om de voorbeelden voor Bob te genereren, waarbij de ene AI wordt gebruikt om een andere te trainen. Alice leerde doelen te stellen, zoals het bouwen van een toren van blokken, deze vervolgens oppakken en balanceren. Bob leerde eigenschappen van de (virtuele) omgeving, zoals wrijving, te gebruiken om objecten vast te pakken en te draaien.
Tot nu toe is de aanpak alleen getest in een simulatie, maar onderzoekers van OpenAI en elders worden steeds beter in het overzetten van modellen die zijn getraind in virtuele omgevingen naar fysieke. Met een simulatie kunnen AI’s in korte tijd door grote datasets bladeren, voordat ze worden verfijnd voor real-world instellingen.
De onderzoekers zeggen dat hun uiteindelijke doel is om een robot te trainen om elke taak op te lossen die iemand hem zou kunnen vragen.
Anderen lazen ook


